Autoencoder (自己符号化器) のデモを作った.これまで何度かこのブログでも書いてきた学習器は, ある入力が与えられると,それが何でありそうかという予測 (推定ラベル) を返す推論系のものが多かった.例えば1桁の手書き数字画像を与えると,10個の要素 (各要素は0以上1以下に正規化されているため,これらの値を確率として扱うことができる) の出力ベクトルが得られる.このベクトルのなかで2番めの要素が大きかったならば「この数字は2なのだろう」という具合に解釈する.
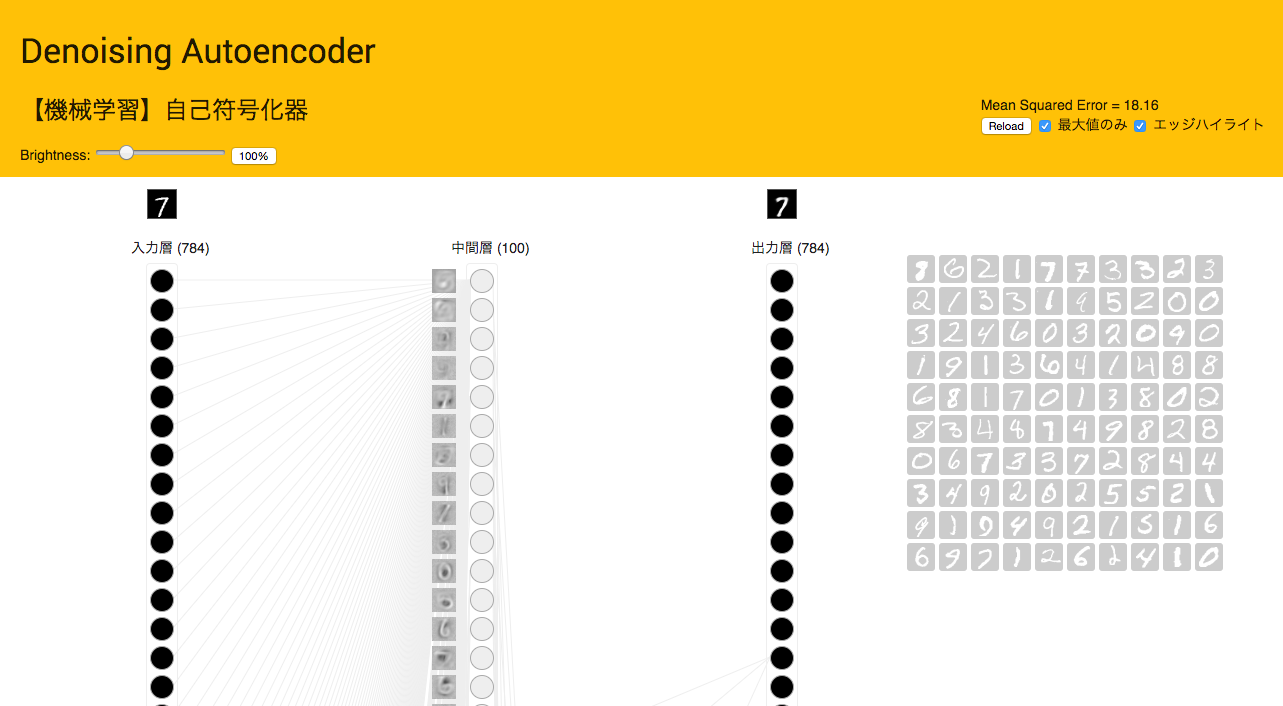
一方Autoencoderでは,入力で与えられたものと同じ形状の出力が得られる.縦横28px (要素数28✕28のベクトル) の白黒画像を与えたら,最終出力もこの形状の画像として描画できる. 単層のAutoencoderを考える場合,入力層と出力層の間には一つの中間層が含まれる.この層で,入力画像の抽出が試みられる(機械学習ぽくなってきた).この流れで,中間層のノード数を入力層のノード数よりも小さくして,出力層で入力とほぼ同じ画像を生成できたなら,それはより少ない次元数で入力データの特徴を捉えられるようになったということである.これができると
- 今後の訓練で使うデータの次元下げをできる
- 元データから似た画像を沢山生成して訓練データセットの水増しをできる
という感じで,ありがたい.
Autoencoderの入力層->中間層の重さ行列(中間層->出力層の重さ行列は,入力層->中間層のものを転置したもの)を調整する行程では,入力画像をそのまま使うのではなく画像に幾らかノイズを入れたものを使う.今回は以下の二種類のノイズを試した.
- ガウシアンノイズ
- 正規分布に従ってランダムな値を足してノイズを入れる
- ごま塩(Salt-pepper)ノイズ
- ランダムに黒色のドットを挿入する(情報を欠落させる役割)
- ランダムに白色のドットを挿入する
MNISTのデータセットを使って学習したときのそれぞれのノイズでのデモの様子はこんな感じになる.入力層のノード数は784, 中間層のノード数は100としてある.重み行列を可視化してみると,ガウシアンノイズの方が数字の形がくっきりと現れた.(中間層の左横の灰色正方形たちが,重さ行列を可視化したもの)
Salt-pepper ノイズ

ガウシアンノイズ
Autoencoderの実装はTensorFlowなどの機械学習で便利なライブラリは使わずに,『ゼロから作る Deep Learning』を読みながらNumPyだけで書いてみた.本でAutoencoderが取り上げれているわけではないけれど,自分でネットワークを構成するための考え方や作法が沢山詰まっている.

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
- 作者: 斎藤康毅
- 出版社/メーカー: オライリージャパン
- 発売日: 2016/09/24
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (5件) を見る
今回作ったやつを多層にした Stacked Denoising Autoencoder のデモや,重み行列を可視化する話,結果を描画している部分の開発話もしたいので,また書きます.