背景
Gemini FlashのObject detectionやOCRの性能が向上したという噂を聞いたり、実際にGoogle AI Studioで遊んだりして可能性を感じていた。写真を入力として「犬・猫」や「ガラス製品」など検出対象が明確なタスクでは概ねうまく動く手応えがあった。今回はスクリーンショットに対して「画像の代表領域」「最も重要な領域」「価値の高い情報を提供する箇所」のような漠然としたクエリでの切り抜きができるかを検証したい。
Crop with AI機能
画像内の重要な領域を特定してアノテーション作成を補助するPhonnoの機能。これまでは画像の理解のために Cloud Vision APIの Detect crop hints | Cloud Vision API | Google Cloud を使っていた。Phonnoにおいてこの注釈情報は、テキストと画像を使って画像を検索するための画像IMEで活用される。人間による手作業での範囲指定の手助けをしたい。
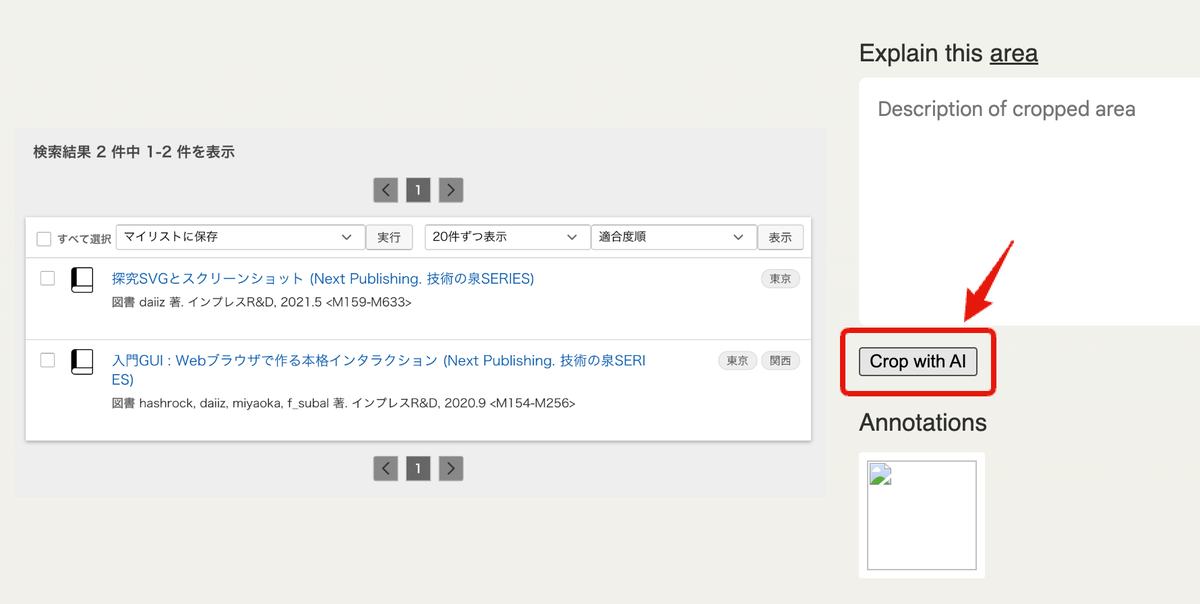
これまでの課題
- クロップ領域決定の精度がイマイチ
- ほとんどのケースでX、Y方向のどちらかしか切り取られない(領域の width, height のどちらかは 100% ということ)。だいぶ長く観察していたけれどほぼこれだった。画像の中心あたりの一部分をくり抜くようなことができない。
- 領域に対する説明を生成できない
- 他のマルチモーダルLLMの力が必要になる
Geminiに差し替えた所感
- Cloud Vision APIよりは可能性を感じる
- まだ満足はできていない。使い手として、さらなる研究が必要。
- 領域のバウンディングボックスと説明を同時に生成できて嬉しい
小手先テクニック
- 画像バイナリだけでなく、別のタスクでo4-miniで生成済みの画像の視覚的説明も一緒に与えることで切り抜き精度が高まる
- 一流のマルチモーダルモデルならこのへんのヒントなしでもいい感じに動いてほしいところなのだが...
- 同様に、画像のサイズ情報 (width, height のピクセル値) も文字で渡すことでinvalidな領域が返ってくる確率が下がる
- これをサボると全体の大きさをはみ出すような座標を返しがち
- 画像サイズが小さいほうが安定する
- 長辺を600pxくらいにリサイズしてから渡している(Geminiの入力画像は3072pxまでいけたはずなのでモデルがもっと賢くなれば不要な処理なはず)。これ以上小さくすると文字の視認性が悪くなる。
- プロンプトエンジニアリング
- まだ試行錯誤が必要っぽい
- 座標を
{ x0: ..., y0: ..., x1: ..., y1: ... }のような形式で返させるよりも、OpenCVやTensorFlowなどでお馴染みの[y0, x0, y1, x1]の配列で要求したほうが良い結果が得られた
具体例
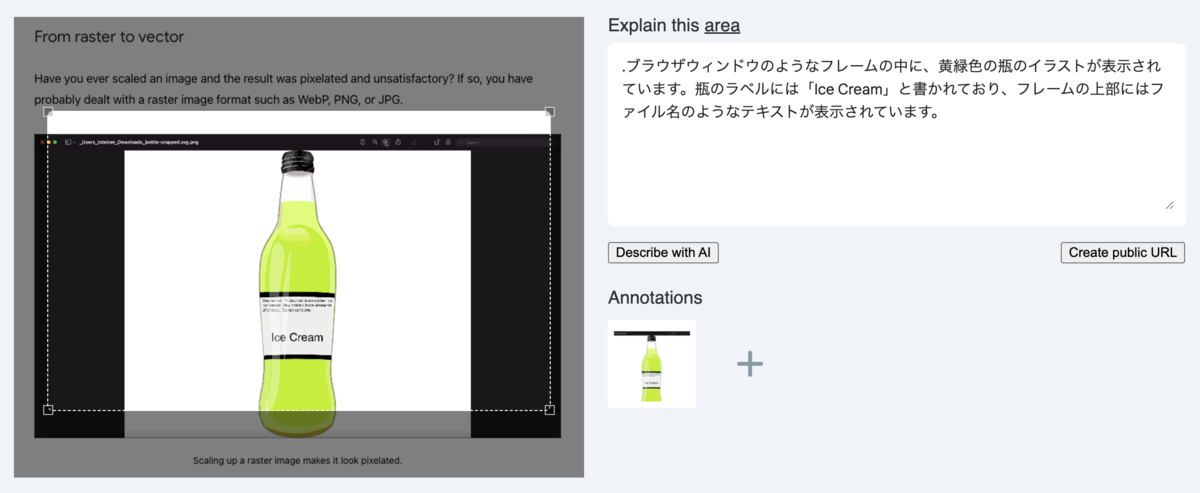

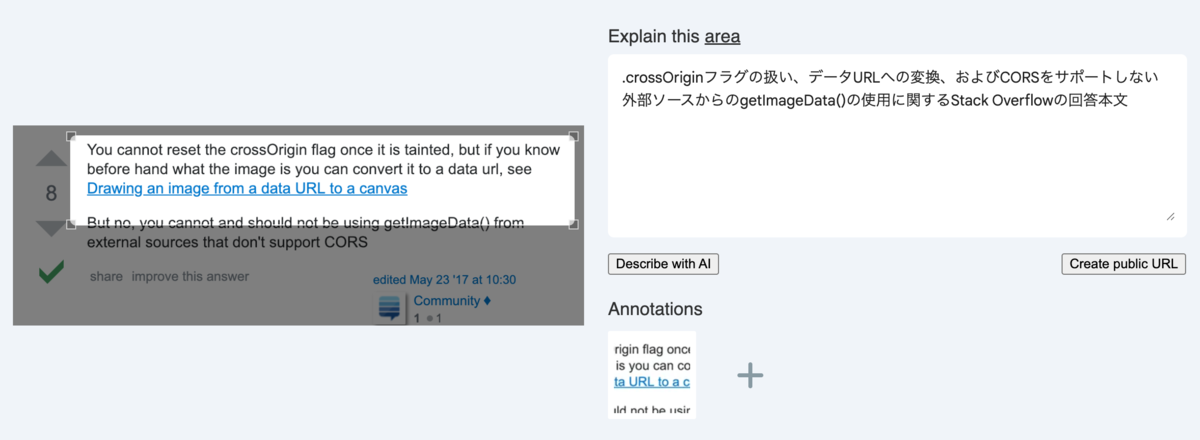
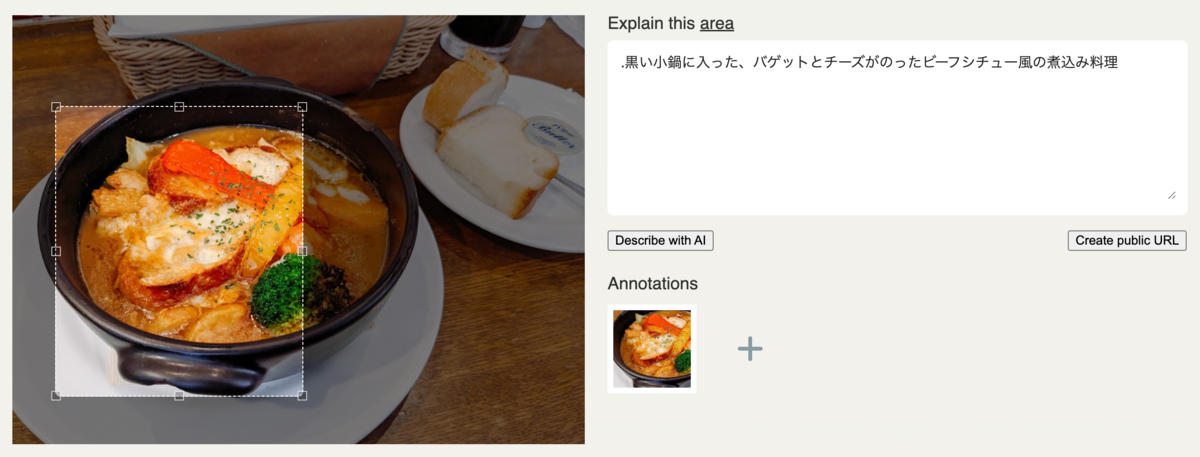
具体例と理想
人間として期待するクロップ領域もあわせて載せてみる。この座標に近づけるためにプロンプト調整を頑張るべきか、いよいよfine tuningの出番なのか、実はGeminiの改善を待っているだけでいいのか。まだ分かっていない。
写真での例

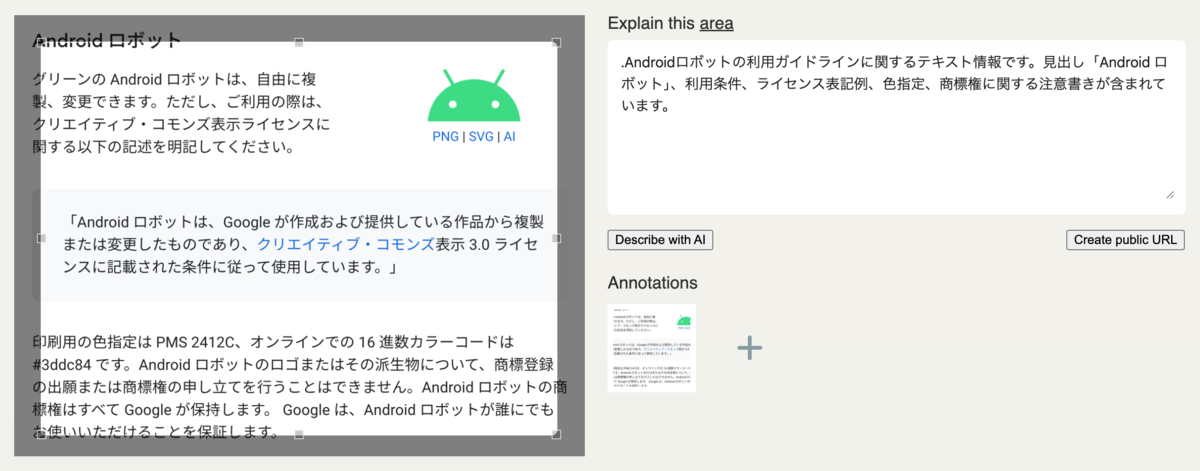
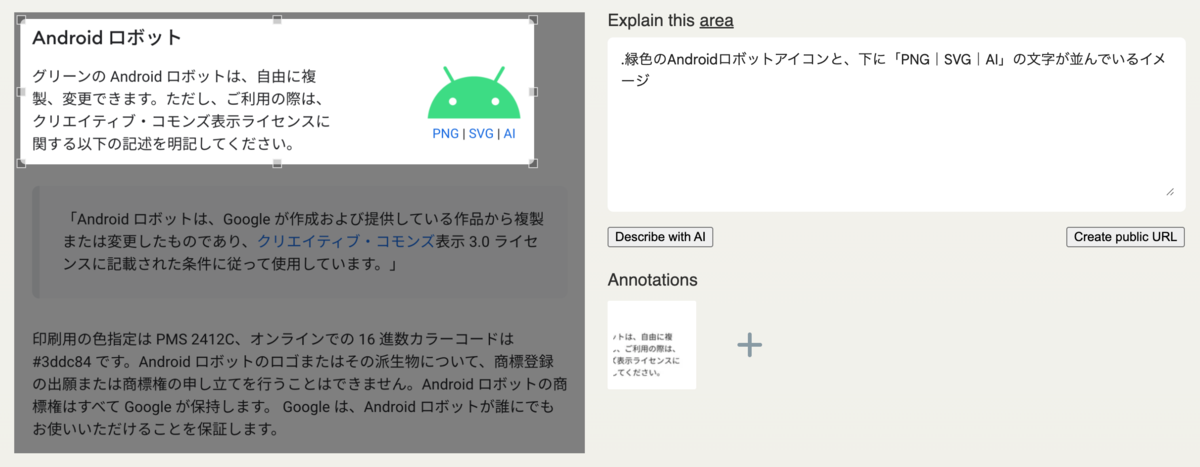
スクリーンショットでの例 ①
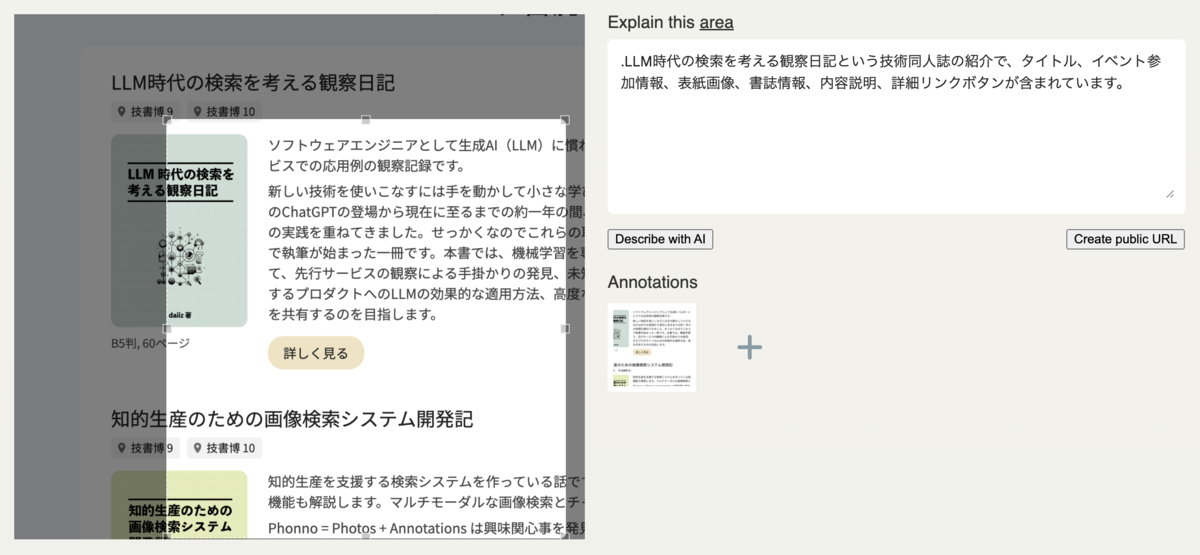
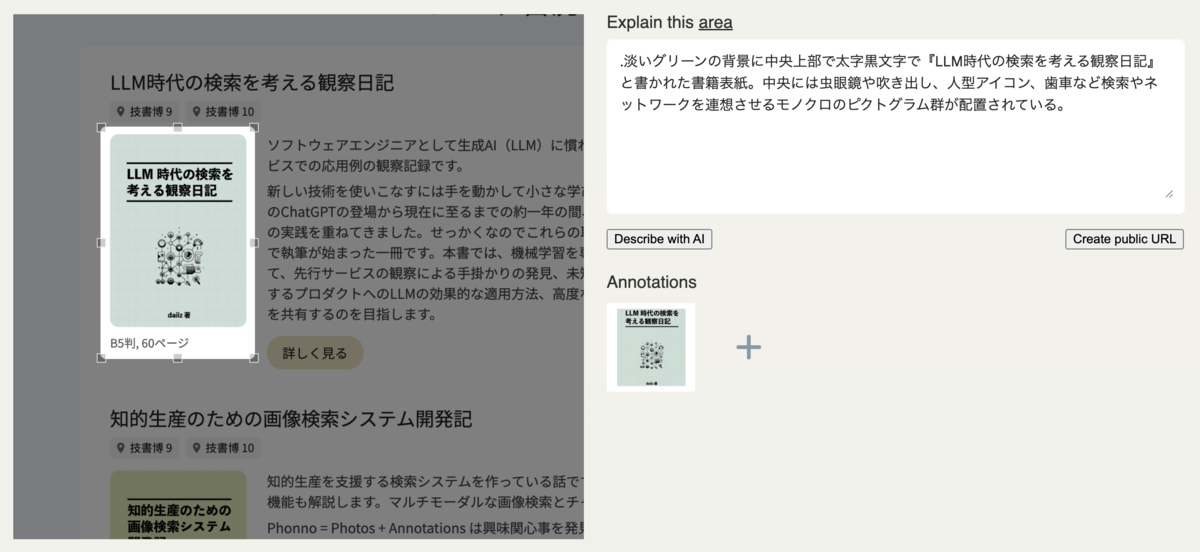
スクリーンショットでの例 ②
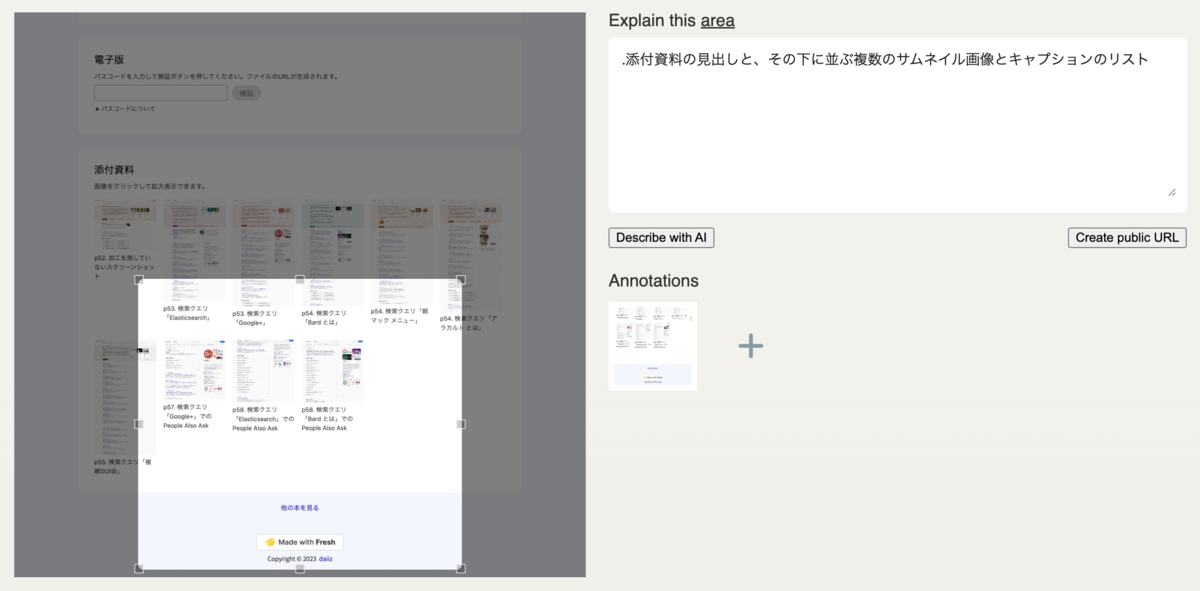
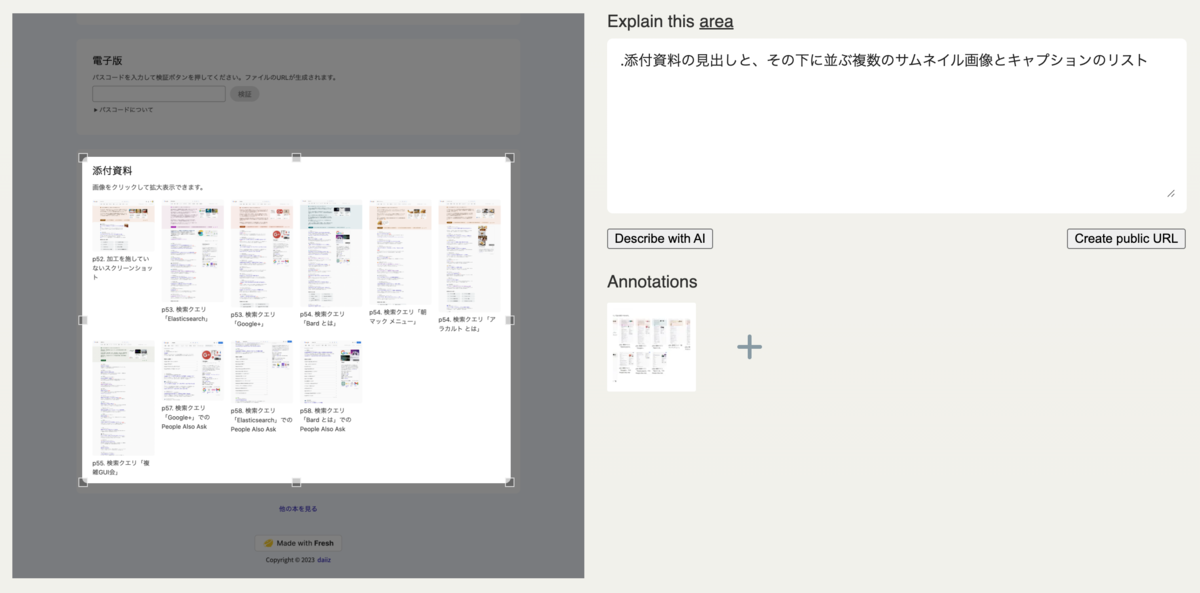
スクリーンショットでの例 ③
FAQ
- すでに https://phonno.org/apps でも使えますか?
- 使えます。Cloud Vision APIよりも安くなった(はず)なのでありがたい。
- o4-miniで視覚的説明を生成したついでに座標も答えさせるとよいのでは?
- たしかに
- 一方で、Geminiのマルチモーダル性能に賭けて使っていきたい気持ちもある
- gemini-2.5-pro-preview-05-06 ではどうでしたか?
- flashの結果とあまり変わらなかった
- 推論時間が長くなりすぎたので採用しなかった